

How AI Agents Are Finding the Biotech Deals Analysts Miss
The most valuable drug asset in biotech right now might be one nobody has heard of.
Not because it is secret. Because it is disclosed in Chinese clinical trial registries, described in Japanese patent filings, published in Korean academic journals, and discussed on Russian-language conference sites. The company behind it has never engaged a US investment bank. No Wall Street analyst has ever written a research report about it.
Over 85% of global patent applications now originate outside the United States. China alone accounts for nearly half of all patents filed worldwide and roughly 30% of global drug development — more than 1,200 novel candidates. The gap between where assets exist and where English-language search tools look represents a multibillion-dollar blind spot for every biopharma company and investment firm.
A multi-agent AI framework called Hunt Globally attacks this problem directly. At its core is the Bioptic Agent — a tree-structured, self-learning AI system that searches across 8+ languages and data sources to find drug assets that standard tools miss.
“Missing a single qualifying asset can mean losing a top partnering or acquisition opportunity worth billions.” — Gayvert et al., arXiv:2602.15019
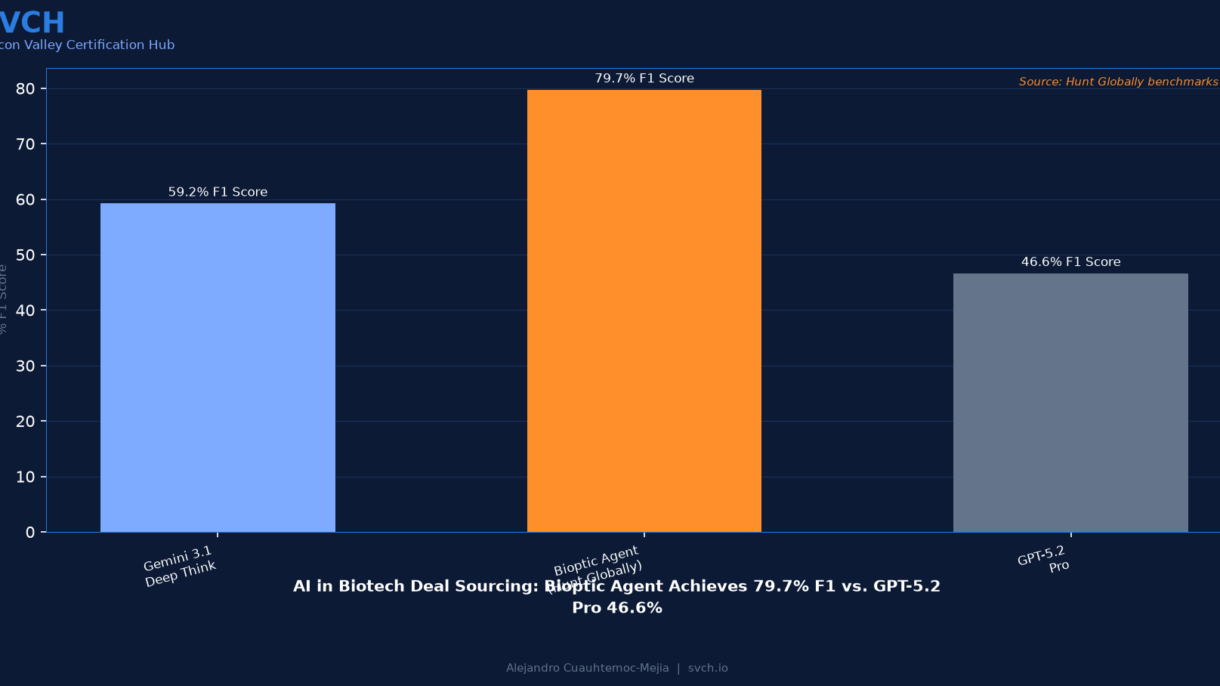
Bioptic Agent (79.7% F1) beats GPT-5.2 Pro (46.6%), Claude Opus 4.6 (56.2%), Gemini 3.1 Deep Think (59.2%), and Perplexity Deep Research (44.2%) on the BiotechAS benchmark of 72 real-world drug asset scouting missions
For CEOs, heads of business development, and chief strategy officers, this paper answers a question that has become urgent: when the best raw intelligence is hidden in a dozen languages and thousands of sources, how do you find what matters before your competitors do?
Executive Summary
The core problem: Over 85% of patents originate outside the US. Standard deep research AI agents default to English sources and miss assets disclosed only in Chinese, Japanese, Korean, Russian, Spanish, and Portuguese channels. The result: systematic blind spots in competitive intelligence and M&A deal sourcing.
The paper’s contribution: Hunt Globally — a multi-agent AI framework with the Bioptic Agent — a tree-structured self-learning system that searches across 8+ languages simultaneously using curated regional source lists.
The finding: Purpose-built AI agents using language-parallel, tree-structured search beat general-purpose frontier models by 20-33 points on biotech deal scouting. The gap is architectural, not fixable with better prompting.
Three Threats Your CI Process Faces
- Your search is English-centric in a non-English world. General models default to English sources even when asked to search globally. The problem is architectural.
- Your competitors already use specialized AI. Bioptic.io’s API already has paying customers — investors and BD professionals using it for real deal sourcing.
- You compete on effort in an era where effort is programmable. The Bioptic Agent covers 8+ languages autonomously. The bottleneck is no longer analyst time.
Paper at a Glance
| Metric | Value |
|---|---|
| Title | Hunt Globally: Wide Search AI Agents for Drug Asset Scouting in Investing, Business Development, and Competitive Intelligence |
| Authors | Gayvert, Tseo, Amini, Mazoure, de Barros, Moran, Wilson, Tambe, Würfl, McDermott, Coston, Ghassemi, Anderson, Leonard, Riesenfeld, Miller, Mirny, van der Velde, Miller, Page, Wang, Greally, Dudley |
| Affiliation | Bioptic.io (San Francisco) |
| Published | February 16, 2026 (v5 submitted May 14, 2026) |
| Categories | cs.AI, cs.IR, cs.MA, q-bio.BM |
| Relevance Score | 88/100 — First paper addressing AI-powered CI and M&A deal sourcing. New business function: Drug Asset Scouting for Business Development. |
| Paper URL | arxiv.org/abs/2602.15019 |
The Benchmark: BiotechAS — 72 Real-World Missions
| System | F1 Score | Type |
|---|---|---|
| Bioptic Agent | 79.7% | Specialized wide-search (this paper) |
| Gemini 3.1 Deep Think | 59.2% | General-purpose frontier model |
| Gemini 3.1 Pro Deep Research | 58.6% | General-purpose frontier model |
| Claude Opus 4.6 | 56.2% | General-purpose frontier model |
| OpenAI GPT-5.2 Pro | 46.6% | General-purpose frontier model |
| Perplexity Deep Research | 44.2% | General-purpose deep research |
| Exa Websets | 26.9% | Web-only search |
Every frontier model clusters in the 44-59% range. The specialized agent sits at 80%. This is not a distribution of quality — it is a distribution of capability. General models are not slightly worse at drug asset scouting; they are fundamentally unsuited for it.
The Architecture: Why Specialized Agents Win
Language-Parallel Search
The agent searches across 8+ languages simultaneously — Chinese, Japanese, Korean, Russian, Spanish, Portuguese, English — each with curated regional source lists. GPT-5.2 asked to search China defaults to English databases. The Bioptic Agent goes to Chinese Clinical Trial Register, Chinese patent databases, and Chinese-language journals.
Tree-Structured Self-Learning
No fixed search plan. The agent evaluates which sources have been explored, identifies coverage gaps, and autonomously selects the next source type (web, patents, trials, literature) and query strategy. It widens when thin, narrows when sufficient.
Curated Regional Source Lists
The paper invests significant effort mapping the right sources per region. Chinese biotech assets are not disclosed in the same places as Korean or Russian ones. The Bioptic Agent knows where to look because those source lists are explicitly curated.
What This Means for Your Organization
Chief Strategy Officers — Your CI infrastructure is your early warning system. English-centric CI systematically misses 20-40% of relevant market signals. Action: Audit your CI pipeline. Map every source type. If Chinese patent databases, Korean trial registries, and Japanese filings aren’t on that map, you have a structural blind spot.
Heads of Business Development — General-purpose models operate at 46-59% effectiveness on asset scouting. Specialized agents operate at 80%. Action: Run a pilot across 10 therapeutic areas comparing your current tools against a specialized wide-search agent.
Chief Investment Officers (Biotech VC/PE) — The 20-33 point gap represents a structural market inefficiency. Assets found only through non-English channels have fewer competing buyers. Action: Integrate language-parallel search into deal sourcing. Track exclusively non-English-channel opportunities over the next 6 months.
CEOs (Biopharma) — M&A is your primary growth mechanism. If your CI infrastructure defaults to English, you are systematically disadvantaged against competitors with specialized wide-search AI. Action: Reassess your M&A target identification strategy. Justify specialized investment in wide-search AI.
Heads of Competitive Intelligence — The paper provides the first standardized benchmark for evaluating AI-assisted search tools. Action: Use BiotechAS as a vendor evaluation framework for any AI tool your team considers.
The Series Context
| Date | Category | Paper Topic |
|---|---|---|
| May 1-9 | Governance | Safety, Compliance, Insurance, Liability, Market Integrity, Competition |
| May 10 | IP Protection | Prompt Theft Prevention (PragLocker) |
| May 11 | Enablement | Autonomous BI (DIDA) |
| May 12 | Commercial Model | LLM Neuron-Level Advertising |
| May 13 | Regulated Operations | Compliance-Grade LLM Serving for Fraud/AML |
| May 14 | Innovation & IP Generation | AI Patent Generation (IdeaForge) |
| May 15 | Competitive Intelligence & M&A | AI-Powered Global Drug Asset Scouting (Hunt Globally) |
Why it matters: After generating IP (May 14, IdeaForge), the series now addresses finding existing IP invisible to English-centric tools. Generate + discover. New business function: AI-powered competitive intelligence for M&A deal sourcing — AI finding what competitors can’t access.
Actions for this Quarter
IMMEDIATE — CSO: Commission an audit of your CI pipeline. Are non-English sources integrated?
IMMEDIATE — Head of BD: Pilot a specialized wide-search agent against 10 therapeutic areas. Measure the miss rate.
SHORT-TERM — CIO (Biotech VC): Integrate language-parallel search into deal sourcing workflow. This is a measurable alpha source.
SHORT-TERM — CEO: Reassess M&A target identification for structural English-language bias in your CI infrastructure.
MEDIUM-TERM — Head of CI: Develop an industry-specific search benchmark modeled on BiotechAS.
LONG-TERM — Extend wide-search architecture beyond biopharma to any industry where global asset discovery drives competitive advantage.
Conclusion
The most important number in this paper is not 79.7%. It is the gap: 20 to 33 percentage points between specialized and general-purpose AI for drug asset scouting. That gap is a direct measure of competitive intelligence advantage. Every month relying on English-centric general models for global asset discovery is a month competitors with specialized agents operate at a 20-33 point information advantage.
The architecture is proven. The benchmark is public. The product has paying customers. The question is not whether specialized wide-search AI works — it does, definitively. The question is how quickly organizations will restructure their competitive intelligence infrastructure around it.
For biopharma companies and healthcare investors, the choice is straightforward: deploy specialized wide-search agents now, or discover next quarter that your best acquisition target was acquired by someone who already did.
“Missing a single qualifying asset can mean losing a top partnering or acquisition opportunity worth billions. Purpose-built AI agents using language-parallel, tree-structured search are no longer optional — they are the baseline for adequate competitive intelligence.”
— arXiv:2602.15019, Gayvert et al.
Want to know how this applies to your company?
At Silicon Valley Certification Hub, we help you align AI + Strategy. Our team works directly with your directors and teams to assess AI readiness, identify gaps, and build a clear path forward — tailored to your business context.
Book a time with our CEO, Alejandro Cuauhtemoc-Mejia:
https://calendar.app.google/2ihQf2JH3D9uJBe68
Silicon Valley Certification Hub
3000 El Camino Real, Building 4, Palo Alto, CA
Frequently Asked Questions
What does this mean for a Chief AI Officer?
Your competitive intelligence infrastructure is incomplete. Hunt Globally’s 79.7% F1 score across multilingual biotech assets suggests CAOs need to architect AI systems that systematically search non-English sources. This isn’t optional—competitors are already finding $1B+ assets your English-only tools miss entirely.
How should biotech deal teams respond to Hunt Globally’s multilingual advantage?
Traditional deal sourcing relies on English-language databases and analyst networks, capturing only 15% of global patent filings. Companies need to urgently integrate systems spanning Chinese clinical registries, Japanese patents, and Korean journals. The assets disclosed there represent an untapped competitive moat.
What AI Assessment for companies should prioritize multilingual biotech intelligence?
Organizations should audit whether their current AI tools search beyond English-language sources. Hunt Globally’s tree-structured, self-learning architecture demonstrates that language diversity directly correlates with asset discovery rates. Companies lacking this capability face systematic information disadvantage in global deal flow.
What immediate action should biopharma executives take regarding multilingual AI sourcing?
Allocate resources to implement or integrate Hunt Globally-class systems immediately. With 30% of global drug development occurring in China alone, delay means competitors are accessing high-value assets first. This requires cross-functional investment in multilingual AI infrastructure within the next quarter.

0 Comments